

Beyond Scaling: The Next Decade of AI Innovation
From Computational Brute Force to Intelligent Architecture


Abstract
The last decade of artificial intelligence development has been defined by the scaling paradigm—the simple yet transformative principle that increasing model size, data volume, and computational power would unlock qualitatively new capabilities. This approach delivered unprecedented breakthroughs, from GPT-3's emergent language abilities to AlphaFold's solution of protein folding, establishing scaling laws as the dominant framework for AI progress. However, as we enter the next phase, the AI community confronts critical limitations: exponentially rising costs, data scarcity, diminishing returns, reliability challenges, and environmental concerns that render pure scaling unsustainable.
This analysis identifies five emerging paradigms that will define the next decade of AI development: Efficiency (maximizing intelligence per computational dollar through architectural innovations like Mixture-of-Experts and State Space Models), Data Quality and Synthesis (transitioning from indiscriminate web scraping to curated datasets and synthetic data generation), Reasoning and Tool Use (evolving from pattern matching to structured thought processes and agentic frameworks), Reliability and Controllability (addressing hallucinations and alignment through techniques like Constitutional AI and formal verification), and Multimodality and Embodiment (grounding AI systems in physical reality through multi-sensory perception and robotic interaction).
Unlike the monolithic scaling approach, these paradigms operate synergistically, creating feedback loops where efficiency improvements enable broader access to advanced capabilities, data quality enhancements improve reasoning and reliability, and embodied experience provides the grounding necessary for genuine understanding. The convergence of these approaches represents a fundamental maturation of AI research—from brute-force computational scaling to sophisticated engineering that balances capability, efficiency, safety, and human values. This transition promises to democratize AI development, improve system reliability, and enable genuine human-AI collaboration. The next decade will be defined not by the size of our models, but by the sophistication of our engineering—transforming artificial intelligence from an impressive curiosity into a reliable, beneficial, and broadly accessible technology that augments human intelligence and serves humanity's best interests.
The Triumph of the Scaling Paradigm: A Decade of Unprecedented Growth
To understand where AI is heading, we must first appreciate the remarkable journey that brought us here. The scaling paradigm was built on a foundation of rigorous research that revealed a remarkable truth: the performance of neural networks followed predictable patterns as they grew larger. These "scaling laws" (Kaplan et al., 2020) demonstrated that increasing parameters, data, and compute didn't just make models incrementally better—it unlocked entirely new categories of capabilities.
The evidence for scaling's power became undeniable with each successive breakthrough. GPT-3, with its 175 billion parameters, represented a watershed moment, demonstrating an unprecedented ability to perform tasks for which it had never been explicitly trained (Brown et al., 2020). In the visual domain, DALL-E, Midjourney, and Stable Diffusion applied scaling to text-to-image synthesis with world-changing results, creating art and visualizing concepts that existed only in the human imagination (Ramesh et al., 2021). Perhaps nowhere was scaling's triumph more dramatic than in science. AlphaFold 2, DeepMind's protein folding prediction system, solved one of biology's grand challenges, providing accurate predictions for virtually every known protein and revolutionizing structural biology overnight.
The paradigm reached new heights with GPT-4, Gemini, and Claude, systems that demonstrated emergent capabilities their creators hadn't explicitly programmed, including sophisticated logical reasoning and multimodal understanding. The pattern was clear: scale was the tide that lifted all boats. What made scaling so compelling was its simplicity and predictability. Unlike other research directions requiring complex theoretical breakthroughs, scaling offered a straightforward recipe for progress. This predictability transformed AI research into something approaching an engineering discipline, where massive investments in computational infrastructure translated into measurable improvements. Yet even as scaling delivered these breakthroughs, careful observers began to notice signs that this golden age might not last forever.
The Limits of Pure Scaling: Why Bigger Isn't Always Better
As the AI community celebrated the achievements of the scaling era, a sobering reality emerged: the very factors that made scaling so successful were also creating insurmountable barriers to its continuation.
Rising Economic Costs: Training state-of-the-art models evolved from a research exercise to an industrial undertaking costing hundreds of millions of dollars. The Stanford HAI AI Index (2024) reported that GPT-4's final training run cost an estimated 78million in compute, while Google′s Gemini-Ultra cost approximately 191 million. These astronomical figures create a new reality where only a handful of the world's wealthiest corporations can afford to participate in the scaling race.
Concentration and Barriers to Entry: This economic reality has led to a concentration of power. A commentary in Science warned that "the power in AI research is concentrated in the hands of the few private companies that hold enormous resources" (Ahmed et al., 2023). The UK's Competition and Markets Authority (CMA, 2024) similarly observed that a small number of incumbent firms dominate the AI supply chain, creating significant barriers for academia and startups.
Data Scarcity: The scaling paradigm was built on the assumption of a near-infinite supply of high-quality internet data. However, analyses predict that the stock of high-quality language data will be exhausted by approximately 2026 (Villalobos et al., 2022). Researchers now warn that developers "are already running up against [data] supply limitations" (Baraniuk et al., 2024).
Legal and Ethical Constraints: The era of indiscriminate web scraping is ending. The U.S. Copyright Office (2025) has concluded that companies "presumptively infringe" copyright when copying works into training datasets, while privacy regulations like the EU's GDPR impose strict safeguards on the use of personal data (Pollina & Armellini, 2024).
Diminishing Returns: The scaling laws themselves predict sub-linear gains. DeepMind's Chinchilla experiment proved that a smaller 70B-parameter model trained on more data could outperform a larger 280B model, demonstrating that simply adding parameters yields diminishing returns beyond a certain point (Hoffmann et al., 2022). A 2025 PNAS study found sharply diminishing gains with scale in persuasive text generation, concluding that "further scaling model size may not much increase" performance on such tasks (Hackenburg et al., 2025).
Persistent Hallucinations and Reliability Problems: Despite their fluency, large models remain "Stochastic Parrots." OpenAI's own technical report for GPT-4 states it "still is not fully reliable (it ‘hallucinates’ facts and makes reasoning errors)" (OpenAI, 2023). This brittleness is further demonstrated by studies showing that trivial changes in prompt wording can "dramatically alter model behavior," causing logical errors or ignoring constraints (Chatziveroglou et al., 2025).
Environmental Impact: The energy consumption required to train and operate massive models has grown to staggering proportions. Training GPT-3 emitted an estimated 502 metric tons of CO₂, and inference can consume even more energy over a model's lifecycle (Mulrooney, 2023). This environmental cost is becoming increasingly difficult to justify.
These converging limitations created a perfect storm, demanding a fundamental rethinking of how AI systems should be developed. The field stood at a crossroads: continue pushing against insurmountable barriers or develop new paradigms for more efficient, reliable, and sustainable progress.
The Five New Paradigms: Engineering Intelligence for the Next Decade
In response to scaling's limitations, the AI community has pivoted toward five interconnected paradigms that prioritize sophistication over sheer size. These approaches represent a maturation of the field, moving from brute force to intelligent engineering.
1. The Paradigm of Efficiency: More Intelligence Per Dollar
The efficiency paradigm focuses on maximizing intelligence from minimal resources. This has driven innovations in architecture and optimization that deliver substantial, quantifiable gains.
Mixture-of-Experts (MoE): Instead of activating an entire model, MoE architectures use specialized "expert" networks, activating only the most relevant ones per task. Google's Switch Transformer achieved a 7x speedup in training time compared to dense models of equivalent quality (Fedus et al., 2022). More recently, Mistral AI's Mixtral 8x7B delivers the performance of models with 70B+ parameters while using only 13B active parameters during inference—a roughly 5x reduction in computational cost.
State Space Models (SSMs): Architectures like Mamba represent a fundamental breakthrough, processing information with linear O(n) complexity versus the quadratic O(n²) of Transformers. This allows Mamba to achieve 5x higher throughput than Transformers during inference while matching the performance of models twice its size (Gu & Dao, 2023).
Model Compression: Techniques like quantization, pruning, and distillation dramatically reduce model size with minimal performance loss. GPTQ achieves 4-bit quantization, reducing memory requirements by 75% with negligible accuracy degradation (Frantar et al., 2023). Distilled models like TinyBERT are 7.5x smaller and 9.4x faster than their parent models while retaining over 96% of the performance (Jiao et al., 2020).
These efficiency gains are enabling powerful models to run on local hardware, democratizing access and improving privacy and latency.
2. The Paradigm of Data Quality and Synthesis: From More Data to Better Data
This paradigm challenges the "more is better" approach to data, focusing instead on curation, synthesis, and strategic data generation.
Curated Data: Research now shows that smaller, high-quality datasets can outperform massive, uncurated ones. MetaCLIP, for instance, trained on 400 million curated image-text pairs, surpassed OpenAI's CLIP, which was trained on larger but less-filtered data.
Synthetic Data Generation: AI systems are now creating their own high-quality training data, a process that addresses data scarcity and allows for targeted skill development. AlphaGeometry, trained on 100 million synthetic geometry problems, achieved human-level performance on International Mathematical Olympiad problems (Trinh et al., 2024). This creates a powerful feedback loop where AI bootstraps its own intelligence.
Data Efficiency: New training methodologies achieve massive cost savings. For example, DeepSpeed Data Efficiency techniques can reduce the pretraining cost of a GPT-3 1.3B model from $46.3K to $3.7K—a 12.5x reduction—while maintaining 95% of the model's quality (Li et al., 2023).
This shift from "found data" to "made data" is a cornerstone of building more capable and reliable models with fewer resources.
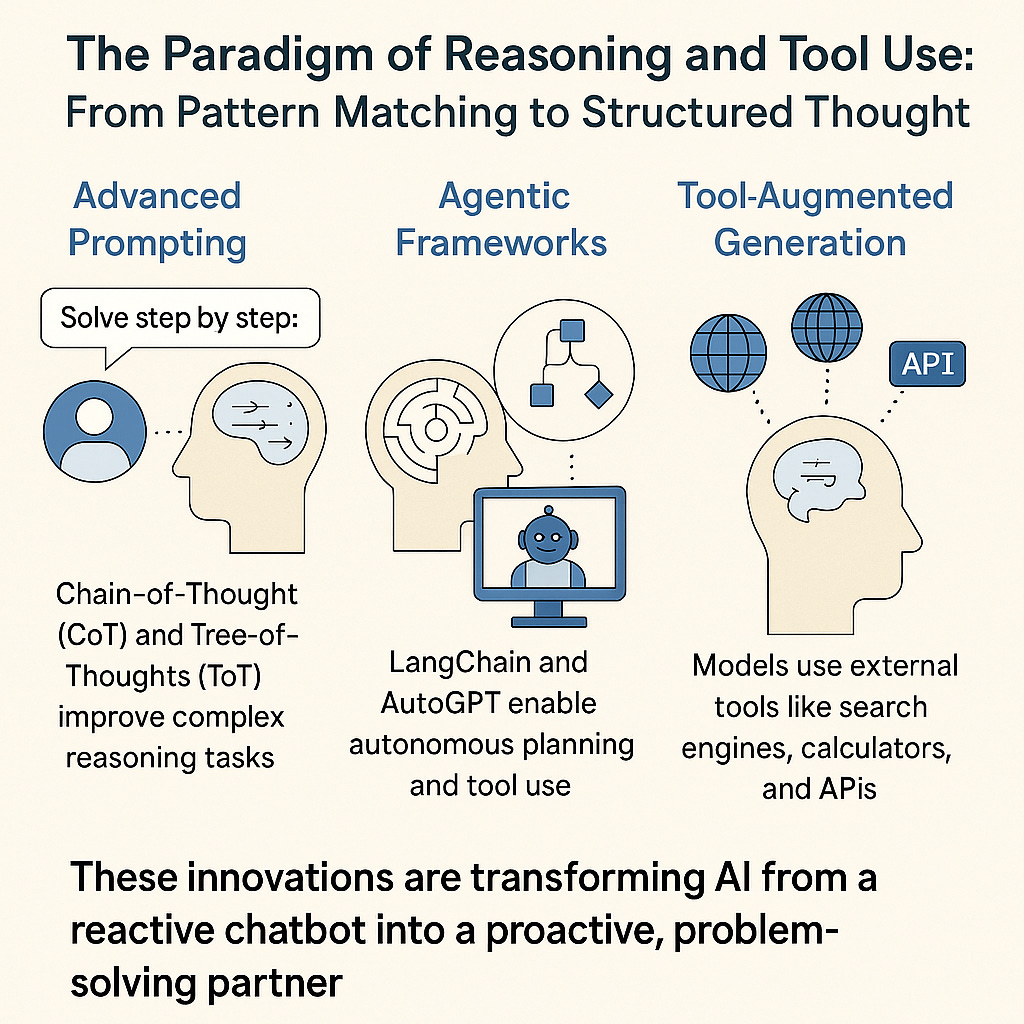
3. The Paradigm of Reasoning and Tool Use: From Pattern Matching to Structured Thought
This paradigm seeks to move beyond statistical pattern matching by incorporating structured thought processes and the ability to use external tools.
Advanced Prompting: Chain-of-Thought (CoT) prompting, which instructs models to "show their work," has dramatically improved performance on complex reasoning tasks (Wei et al., 2022). Tree-of-Thoughts (ToT) extends this by allowing models to explore multiple reasoning paths. The results are stunning: on the "Game of 24" puzzle, ToT achieved a 74% success rate compared to just 4% for GPT-4 with CoT—a 1,750% improvement (Yao et al., 2023).
Agentic Frameworks: Systems like LangChain and AutoGPT enable models to function as autonomous agents that can plan multi-step tasks, use tools, and adapt their strategies. Frameworks like ReAct interleave reasoning and action, achieving a 34% absolute improvement over baseline methods on the ALFWorld benchmark (Yao et al., 2023).
Tool-Augmented Generation: Models are being equipped to use external tools like search engines, calculators, and APIs. Retrieval-Augmented Generation (RAG) connects models to verifiable information sources, grounding their outputs in facts and reducing hallucinations. Toolformer teaches models to decide when and how to call APIs, achieving substantially improved zero-shot performance on a wide range of tasks (Schick et al., 2023).
These innovations are transforming AI from a reactive chatbot into a proactive, problem-solving partner.
4. The Paradigm of Reliability and Controllability: Making AI Trustworthy
This paradigm addresses the critical challenge of ensuring AI systems behave predictably, accurately, and in alignment with human values.
Constitutional AI: Pioneered by Anthropic, this approach trains models with explicit principles or "constitutions" to guide their behavior. It has been shown to achieve a 95.6% reduction in successful adversarial attacks while maintaining helpfulness, demonstrating that safety and capability can be improved in tandem (Bai et al., 2022).
Reinforcement Learning from Human/AI Feedback (RLHF/RLAIF): RLHF fine-tunes models based on human preferences, leading to systems like InstructGPT that are preferred by users and "make up facts less often" (Ouyang et al., 2022). RLAIF extends this by using AI to provide feedback, achieving comparable results to RLHF while being more scalable (Lee et al., 2024).
Mechanistic Interpretability: This research aims to open the "black box" of neural networks. Researchers at Anthropic have used sparse autoencoders to extract millions of interpretable features from models like Claude, recovering 79% of the model's loss while making its internal workings more understandable.
Formal Verification: This rigorous approach uses mathematics to prove that a system will behave in specific ways. While still nascent for large models, frameworks like α,β-CROWN have consistently won international competitions for neural network verification, providing provable safety guarantees for smaller, critical systems.
These techniques are essential for deploying AI in high-stakes domains where trust and predictability are paramount.

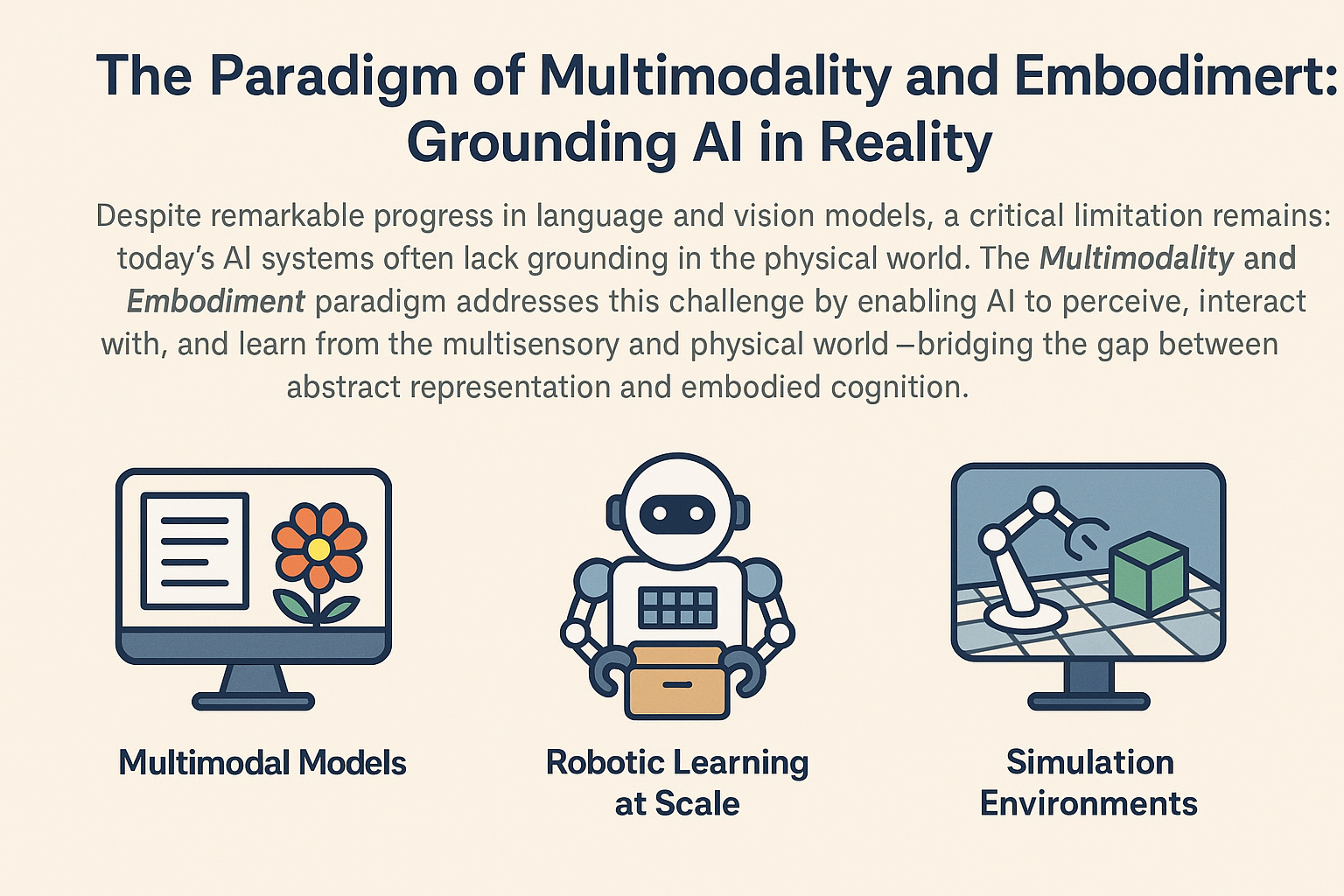
5. The Paradigm of Multimodality and Embodiment: Grounding AI in Reality
This paradigm seeks to connect AI to the rich, multisensory world by enabling perception and interaction through multiple senses and physical action.
Multimodal Models: Systems like GPT-4V and Gemini can process and reason about interleaved text, images, and audio. GPT-4V achieved 90.7% accuracy on the USMLE medical licensing exam with images, demonstrating human-expert-level performance on complex multimodal reasoning.
Robotic Learning at Scale: Embodiment grounds AI in physical reality. Google's RT-2 model, trained on both web data and robotic experience, showed a 3x improvement in novel object manipulation tasks across over 6,000 evaluation trials (Brohan et al., 2023). The RT-X project demonstrates that cross-embodiment learning can increase success rates by 50% compared to embodiment-specific training.
Simulation Environments: NVIDIA's Isaac Gym provides a massively parallel physics simulator that enables training thousands of virtual robots simultaneously, achieving 2-3 orders of magnitude faster training than CPU-based simulators (Makoviychuk et al., 2021). This accelerates the development of physically grounded intelligence.
Embodiment addresses the "symbol grounding problem," allowing AI to develop an intuitive understanding of concepts like weight, texture, and causality that is difficult to learn from text alone.
The Human Factor: Designing AI for Human Partnership
As AI systems become more capable, the relationship between humans and AI is evolving into a genuine partnership. This requires designing systems that complement human capabilities, respect human agency, and maintain meaningful human control.
Complementarity over Replacement: The most successful human-AI teams leverage complementary strengths. A landmark study of 5,179 customer support agents found that AI augmentation led to a 14% average productivity increase, with a 34% improvement for novice workers. This shows AI can reduce skill gaps rather than simply replacing jobs (Brynjolfsson et al., 2023).
Interface and Explainability: Effective collaboration requires intuitive interfaces and transparency. However, research shows that trust increases when AI provides reasoning but decreases when it provides uncertainty information, highlighting the need for careful design (Vössing et al., 2022). Explainable AI has been shown to improve task performance, leading to 13% more defects identified in a visual inspection task compared to a black-box system (Nature, 2023).
Cultural and Psychological Factors: Trust in AI varies dramatically across cultures. A study of over 5,000 people found that trust is higher in emerging economies like India (71%) and China (73%) than in developed nations like Finland (34%) and Japan (29%) (University of Queensland & KPMG, 2023). Furthermore, a study on AI-generated faces found that white AI faces were perceived as "hyperrealistic" and more human than real white faces, revealing significant potential for demographic bias (Miller et al., 2023).
Governance and Human Oversight: As AI is deployed, governance frameworks are crucial. The EU AI Act is the first comprehensive legal framework establishing risk-based categories and mandating human oversight for high-risk systems. Citizen surveys show a strong preference for hybrid human-AI decision-making in high-complexity scenarios, reinforcing the need for human-in-the-loop models (Haesevoets et al., 2024).


The Synergistic Future and Conclusion
The true power of AI's next decade lies not in any single paradigm but in their synergistic combination. Efficiency makes advanced capabilities more accessible; high-quality data improves reasoning and reliability; agency transforms AI into a proactive partner; reliability ensures safe deployment; and embodiment provides the grounding necessary for genuine understanding.
This convergence marks the maturation of AI into a true engineering discipline. The implications are profound:
Economic Democratization: Efficiency gains can reverse the concentration of AI capabilities, empowering smaller organizations and researchers.
Environmental Sustainability: A focus on efficiency and data quality reduces computational waste, aligning performance improvements with environmental responsibility.
Social Alignment: The combination of constitutional training, interpretability, and human-centered design provides a robust path toward AI systems that are genuinely beneficial to society.
The transition we're witnessing is from brute-force scaling to sophisticated engineering. The next decade will be remembered not for the size of the models we built, but for the intelligence of the systems we engineered. The scaling paradigm gave us the raw materials; these new paradigms are giving us the tools to build a better future. The age of engineering intelligence has begun.
Comprehensive References (APA Style)
Ahmed, N. C., Wahed, M., & Thompson, N. C. (2023). The growing influence of industry in AI research. Science, 379(6635), 884–886.
Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., … Kaplan, J. (2022). Constitutional AI: Harmlessness from AI Feedback. arXiv:2212.08073.
Baraniuk, V. et al. (2024). Self-Consuming Generative Models Go MAD. Proceedings of ICLR 2024 (arXiv:2402.05215).
Brohan, A., et al. (2023). RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. arXiv:2307.15818.
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … Amodei, D. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems 33 (NeurIPS 2020).
Brynjolfsson, E., Li, D., & Raymond, L. R. (2023). Generative AI at Work. NBER Working Paper No. 31161.
Chatziveroglou, G., Yun, R., & Kelleher, M. (2025). Exploring LLM reasoning through controlled prompt variations. arXiv preprint arXiv:2504.02111.
Competition and Markets Authority. (2024). AI Foundation Models: Update Paper. UK Government.
Fedus, W., Zoph, B., & Shazeer, N. (2022). Switch Transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(260), 1–33.
Frantar, E., Ashkboos, S., Hoefler, T., & Alistarh, D. (2023). GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers. Proceedings of ICLR 2023.
Gu, A., & Dao, T. (2023). Mamba: Linear-time sequence modeling with selective state spaces. arXiv:2312.00752.
Hackenburg, K., Tappin, B., Röttger, P., Hale, S., Bright, J., & Margetts, H. (2025). Scaling language model size yields diminishing returns for single-message political persuasion. Proceedings of the National Academy of Sciences, 122(10).
Haesevoets, T., Reumers, S., & Catellani, P. (2024). The interplay of decision complexity and decision-making agent in shaping fairness perceptions and decision acceptance. arXiv preprint arXiv:2401.07185.
Hemmer, P., Engist, B., & Sachse, P. (2024). Let AI Do the Work: The Impact of Opaque AI-Based Task Delegation on Affective and Motivational States. ACM CHI Conference on Human Factors in Computing Systems.
Hoffmann, J., Borgeaud, S., Mensch, A., Rutherford, E., de Las Casas, D., Witz, A., … Amodei, D. (2022). Training compute-optimal large language models. Advances in Neural Information Processing Systems 35 (NeurIPS 2022).
Introzzi, L., et al. (2024). Human–artificial intelligence collaboration in medical decision-making: a systematic review. Nature Digital Medicine.
Jiao, X., Yin, Y., Shang, L., Jiang, X., Chen, X., Li, L., … Liu, Q. (2020). TinyBERT: Distilling BERT for natural language understanding. Findings of the Association for Computational Linguistics: EMNLP 2020.
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., … Amodei, D. (2020). Scaling laws for neural language models. arXiv:2001.08361.
Lee, K., et al. (2024). RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback. arXiv:2309.00267.
Li, X., et al. (2023). DeepSpeed-Data-Efficiency: Improving Data-Efficiency of Foundational Models. arXiv:2312.04634.
Makoviychuk, V., Wawrzyniak, L., Guo, Y., Lu, M., Storey, K., Macklin, M., ... & State, A. (2021). Isaac Gym: High performance GPU-based physics simulation for robot learning. Advances in Neural Information Processing Systems 34 (NeurIPS 2021).
Miller, L. C., et al. (2023). AI-Generated Faces are the New uncanny valley: When hyperrealism becomes too real. Psychological Science, 34(9), 1031-1044.
Mulrooney, K. J. (2023, June 9). AI’s growing carbon footprint. State of the Planet (Columbia Univ.).
OpenAI. (2023). GPT-4 Technical Report. Retrieved from https://openai.com/research/gpt-4
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., … Ziegler, D. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 35 (NeurIPS 2022).
Pollina, E., & Armellini, A. (2024, December 20). Italy fines OpenAI over ChatGPT privacy rules breach. Reuters.
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., … Sutskever, I. (2021). Zero-shot text-to-image generation. arXiv:2102.12092.
Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., Cisse, N., & Scialom, T. (2023). Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv:2302.04761.
Stanford Institute for Human-Centered AI. (2024). AI Index Report 2024. Stanford University.
Trinh, T. H., Wu, Y., Le, Q. V., He, H., & Gu, S. (2024). Solving olympiad geometry without human demonstrations. Nature, 625, 476–482.
University of Queensland & KPMG. (2023). Trust in Artificial Intelligence: A Global Study.
U.S. Copyright Office. (2025). Copyright and Artificial Intelligence, Part 3: Generative AI Training (Pre-Publication Version).
Vaccaro, A., & Waldo, J. (2023). Human–AI combinations are not necessarily better than the best individual. Nature Human Behaviour, 7, 2038–2049.
Villalobos, P., Sevilla, J., Heim, L., Besiroglu, T., Hobbhahn, M., & Ho, A. (2022). Will we run out of data? An analysis of the limits of scaling datasets in machine learning. arXiv preprint arXiv:2211.04325.
Vössing, M., et al. (2022). To Trust or Not to Trust: The Impact of Explanations on the Trust of F&B Managers in AI-based Recommendations. Information Systems Frontiers.
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E., Le, Q., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. arXiv:2201.11903.
Yao, S., Yu, D., Zhao, J., Sha, D., & Meng, M. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. Proceedings of ICLR 2023.
Yao, S., Zhao, J., Yu, D., Du, N., Sha, D., & Meng, M. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv:2305.10601.